卷积神经网络(CNN)
卷积神经网络(CNN)
CNN
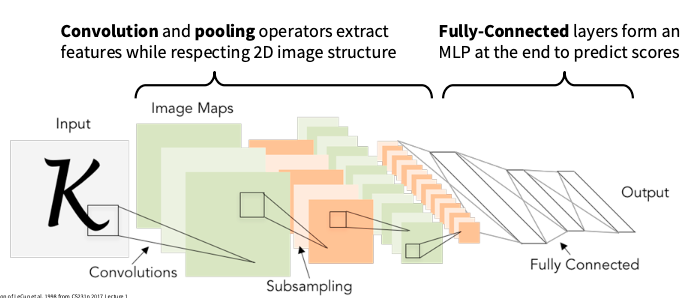
用来提取图像特征,分为两个算子$Convolution\ operrator$ 和$Pooling\ operator$
历史发展
文档分类 $\Rightarrow$ AlexNet(Imagenet 文本分类) $\Rightarrow$ CNN dominate all vision tasks $\Rightarrow$ Transformer 时代
- 文本-Attention is all you need”:NeurIPS 2017
- 图像-An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”, ICLR 2021
卷积层(Convolutional)
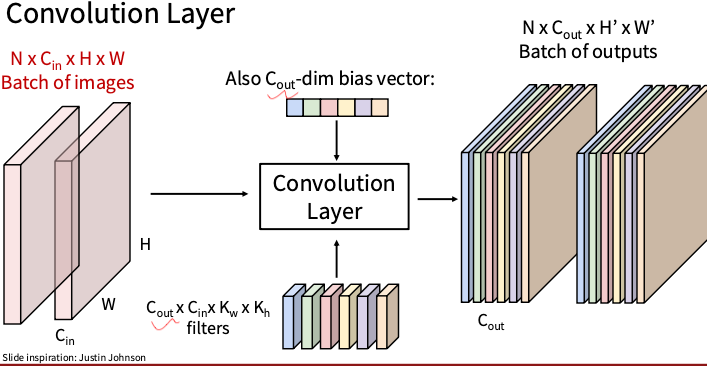
卷积核的通道数和图片的通道数要相同,卷积核从左向右从上向下移动与对应的图像矩阵块做点乘,所以一个卷积核提取得到一个feature map
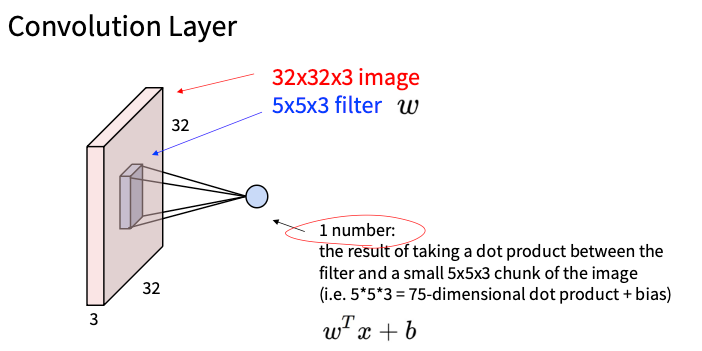

不同的卷积层
- 第一层,浅层的卷积层学到的一般是局部的图像特征(学到一些opposing colors和oriented edges)
- 深层的卷积层学到的一般是larger structures (眼睛,字符等等)
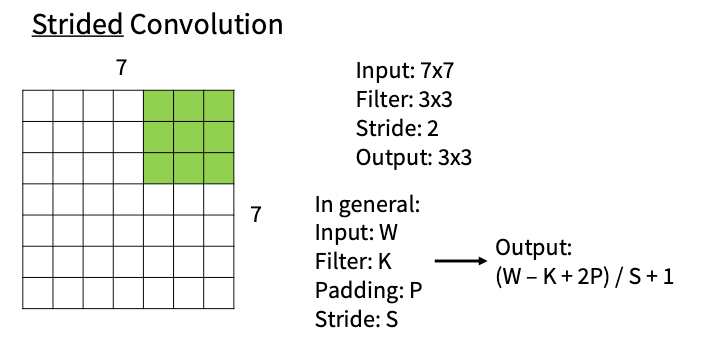
而且由于滑动的性质输出的feature map维度会不断下降,为了防止这个引出Padding 机制
Padding 机制
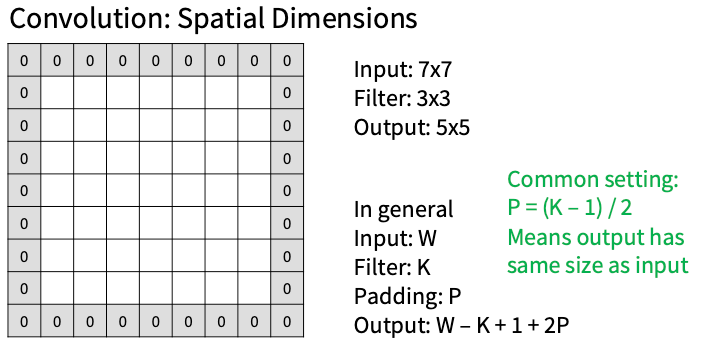
Number of learnable parameters的计算:
Parameters per filter: 355 + 1 (for bias) = 76
10 filters, so total is 10 * 76 = 760
Number of multiply-add operations的计算:
- 先算output的数:10*32*32 = 10,240 outputs
- 再算得到每个output需要的操作数: Each output is the inner product of two 3x5x5 tensors (75 elems)
- Total = 75*10240 = 768K
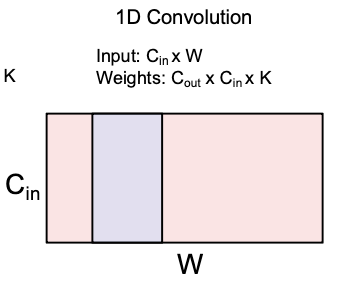
1D Convolution
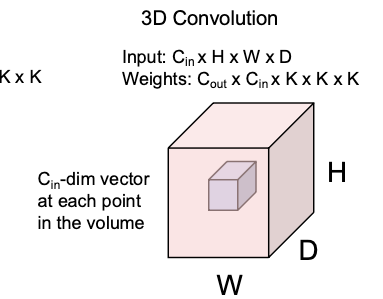
3D Convolution
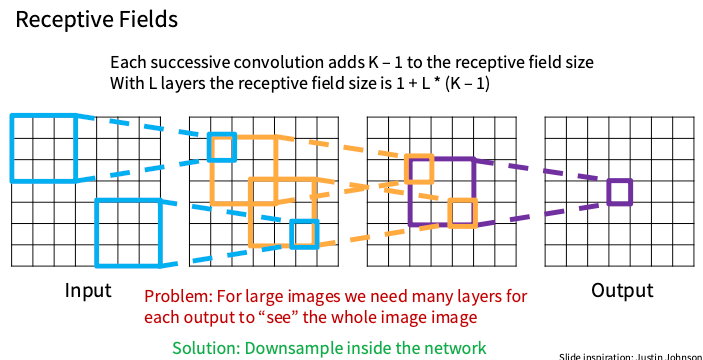
感受野
池化层(Pooling,降采样)
Max Pooling
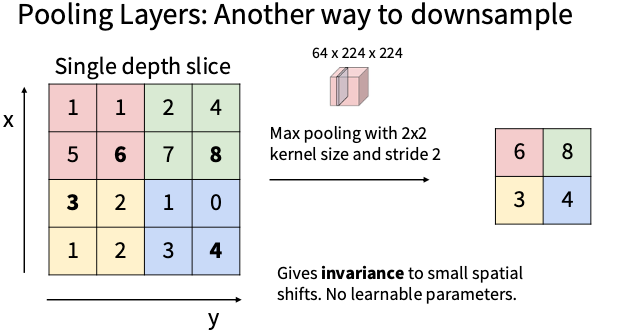
也和卷积核一样滑动进行操作
This post is licensed under CC BY 4.0 by the author.