视频理解
视频理解
视频可以看成4D Tensor :$T\times 3 \times H \times W$
占用内存很大: 30 frames/s,每个frames 有640*480个像素,每个像素三个channal,每个channal占1个字节
所以有$3\times 640 \times 480 \times 30$个字节约等于26MB/s
视频分类:给一段视频对视频进行分类
Idea1:在低画质,低帧率大短视频片段上训练,对视频进行降采样处理.
Idea2: Train normal 2D CNN to classify video frames independently(Often a very strong baseline for video classification)
Idea3:Late Fusion(每个frame都用CNN提取之后最后做pooling fuse)
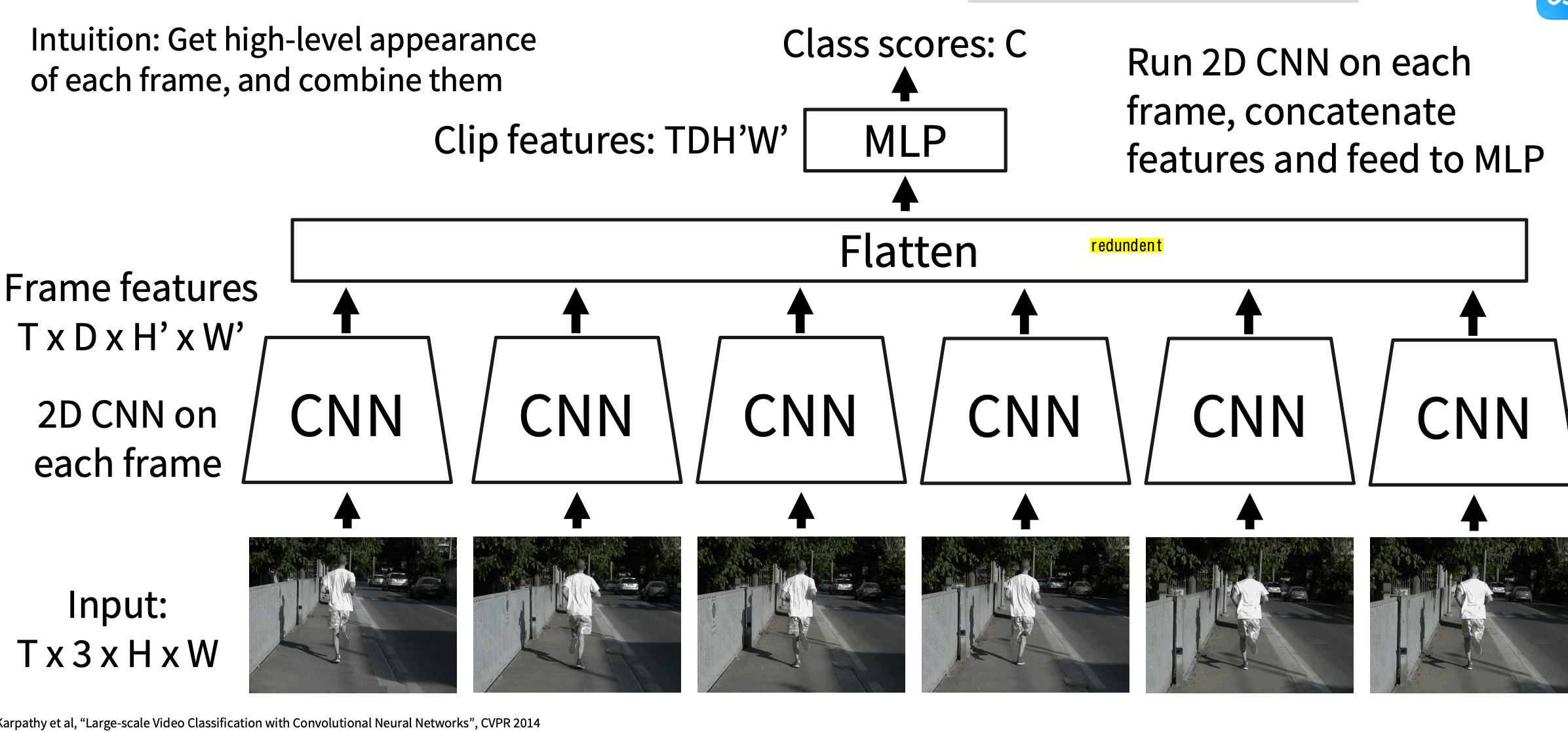

Idea4:Early Fusion(一开始直接将$Channel \times T$ 看成一个整体reshape成通道数然后做CNN Feature extraction)
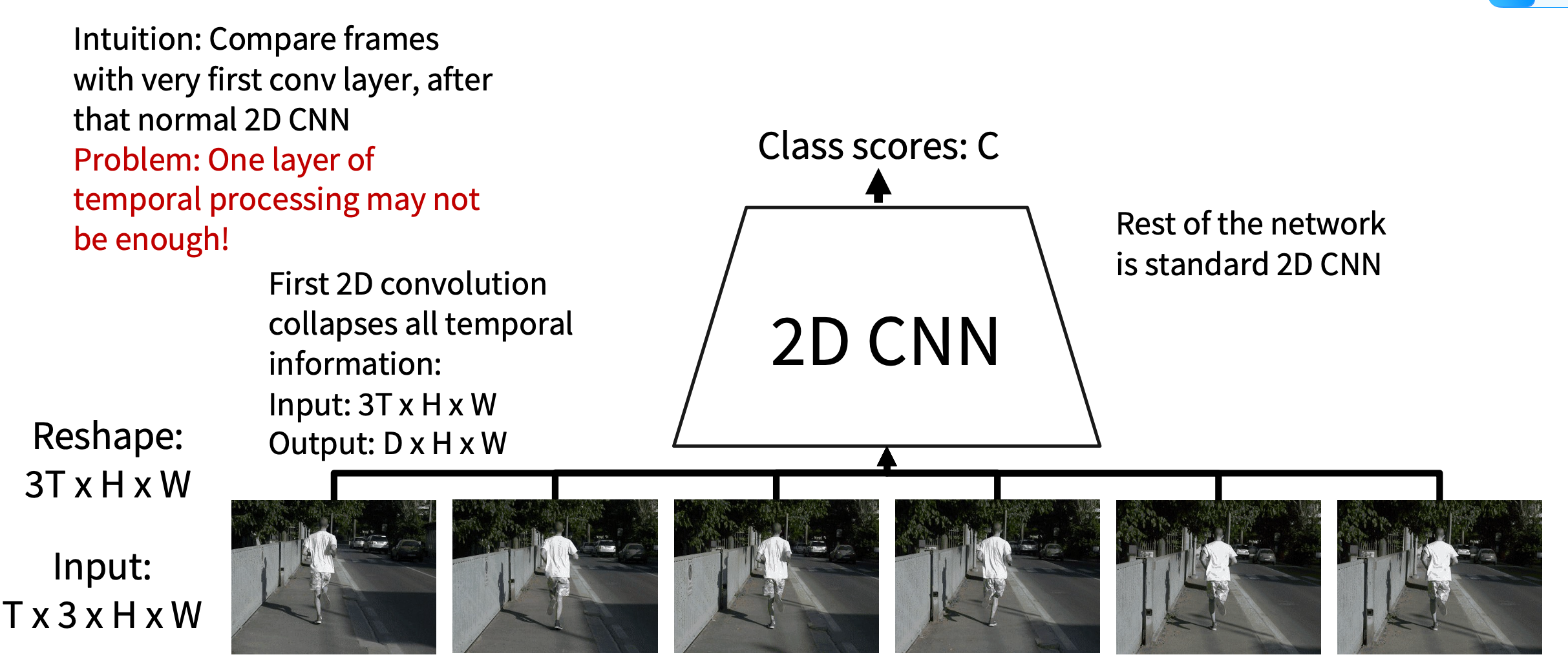
所以不具备时间平移不变性,一个motion出现在不同的time line 的时候在channel的表现不一样需要不同的卷积核来捕捉
Idea5:3D CNN Feature Extraction
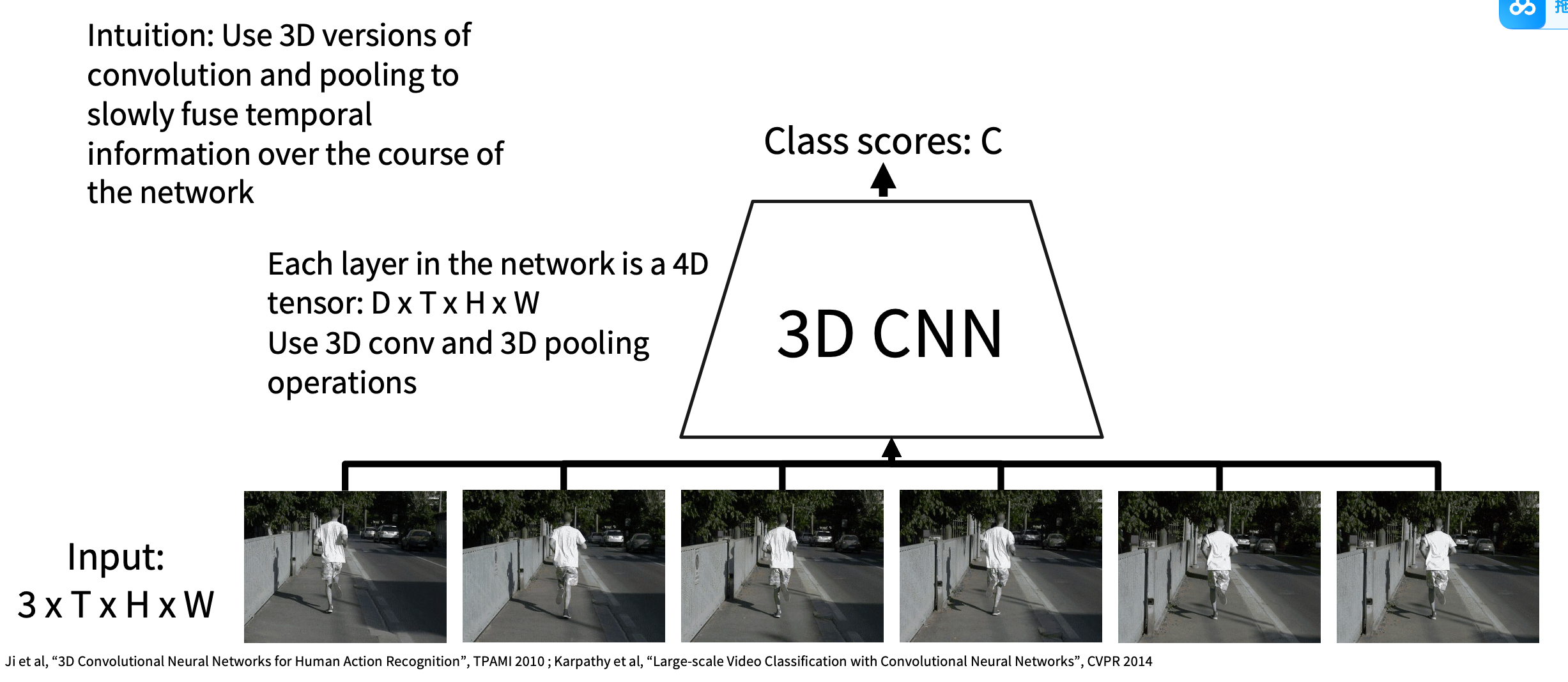
具备时间移动不变性
C3D: The VGG of 3D CNNs(ICCV 2015)
所有的3D CNNs 都采用$3\times 3\times 3$ 的卷积核和$2\times 2\times 2$的pooling
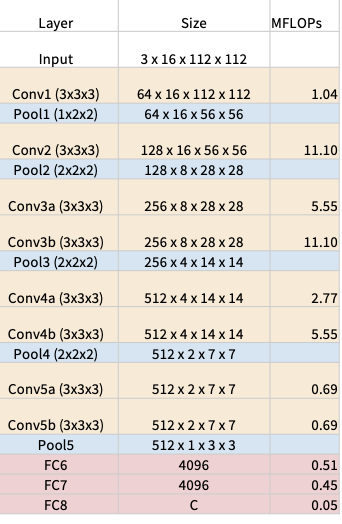
$\color{purple}缺点:太昂贵了,卷积核太多了$
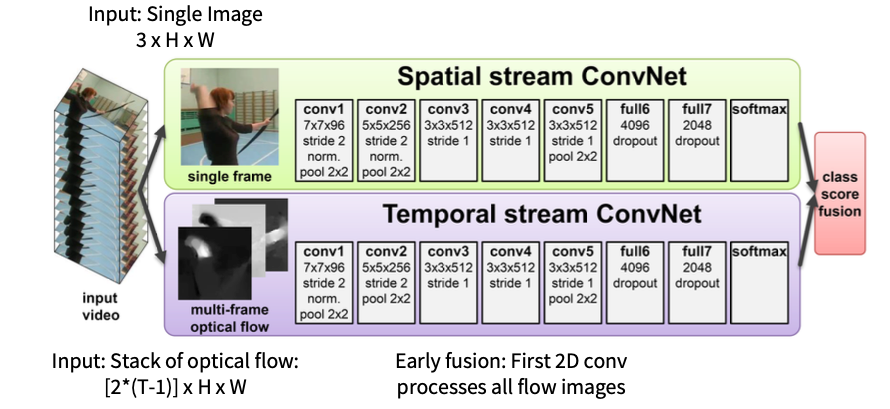
Two-Stream Networks(NeurIPS 2014)
新提出了光流的表征方式
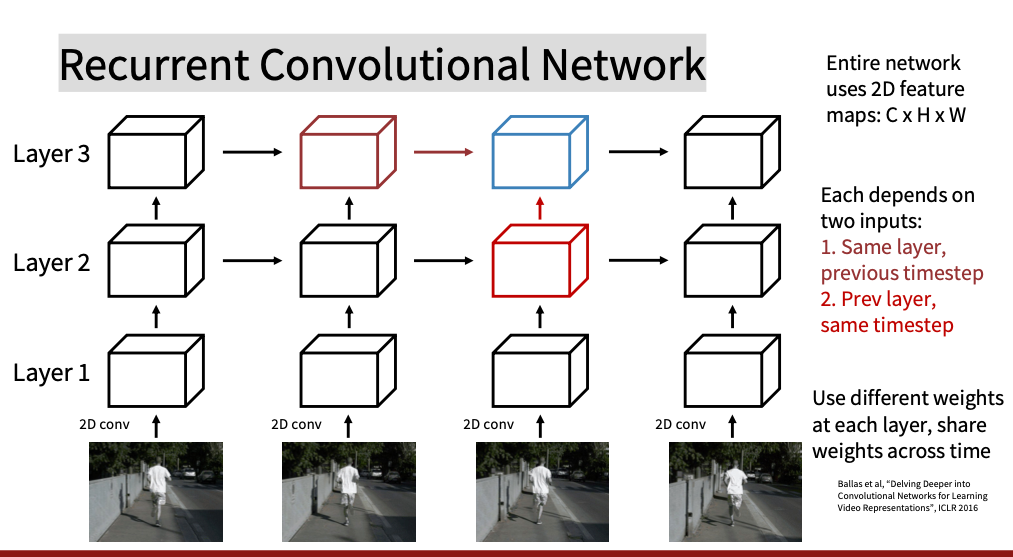
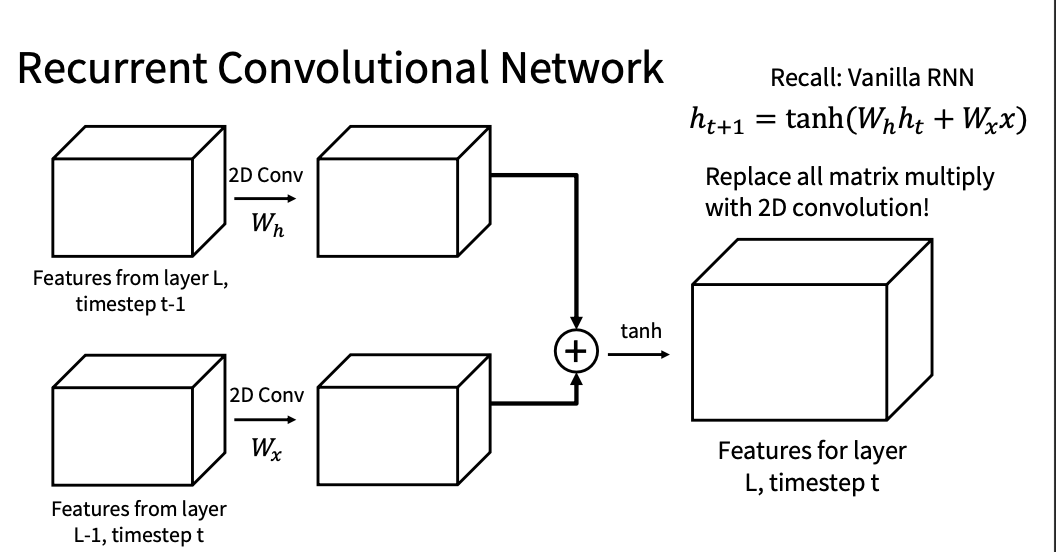
Recurrent Convolutional Network(ICLR 2016)
结合CNN和RNN 来建模长时序特征
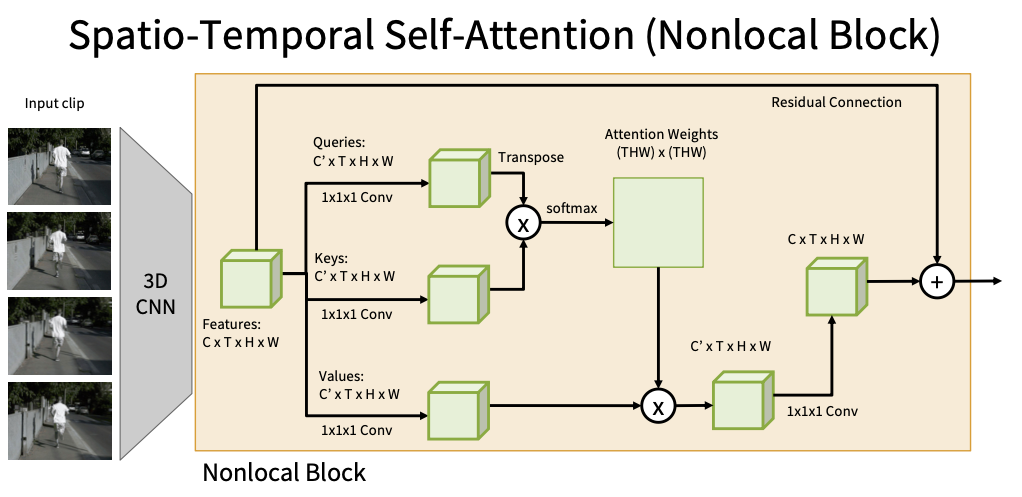
Nonlocal Block(空间时序自注意力)
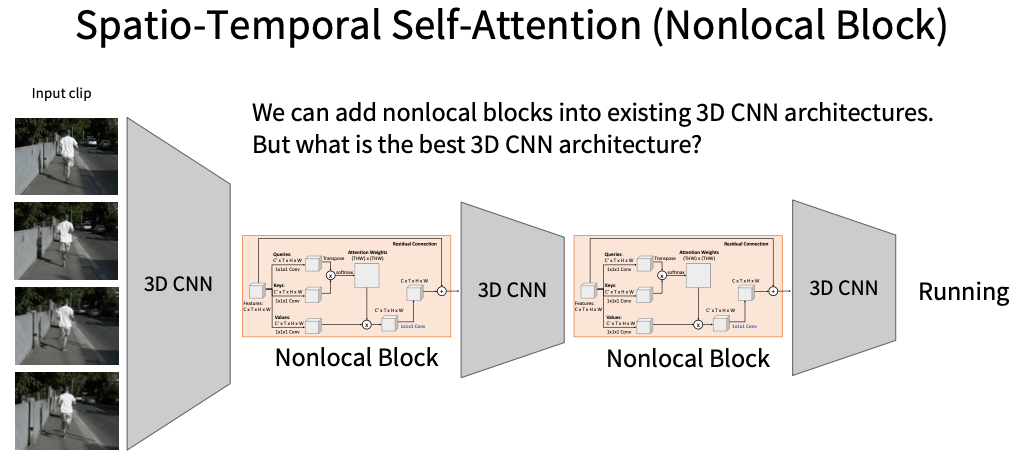
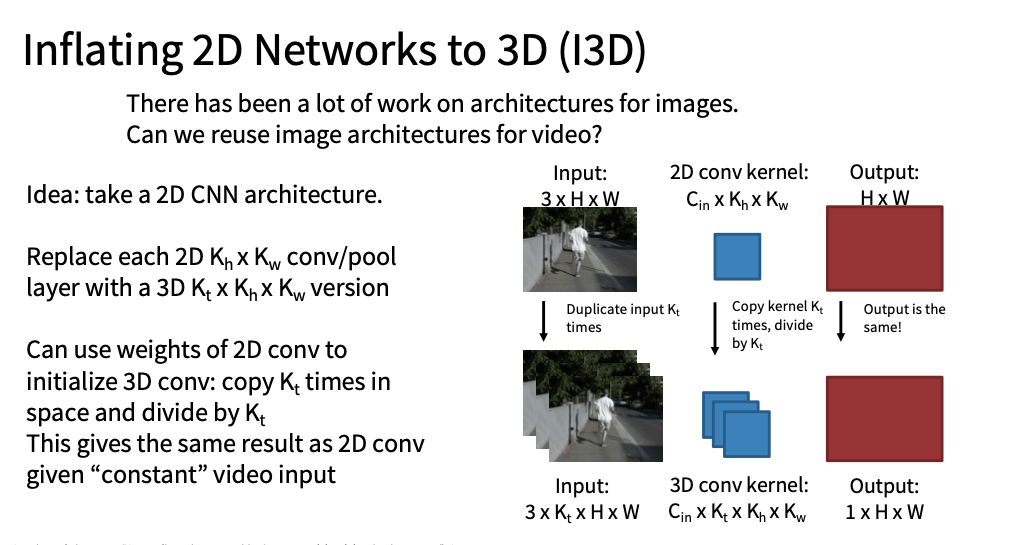
I3D: Inflating 2D network to 3D(CVPR 2017)
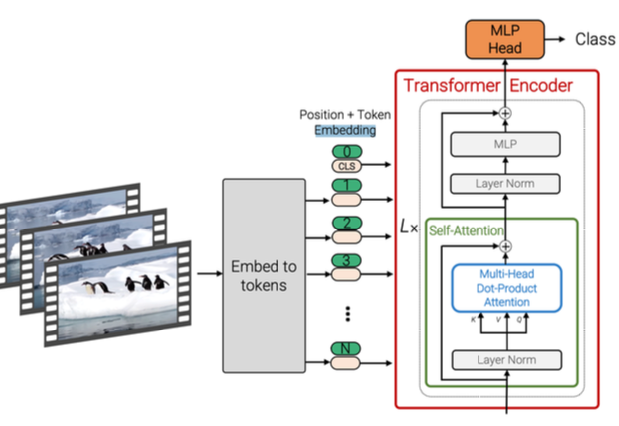
ViViT: Factorized attention(ICCV 2021)
Contribution: Attend over space / time
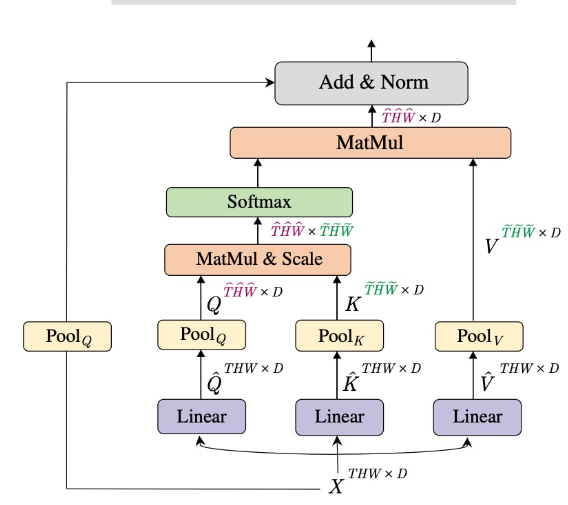
Pooling Module(ICCV 2021)
Contribution : Reduce number of tokens
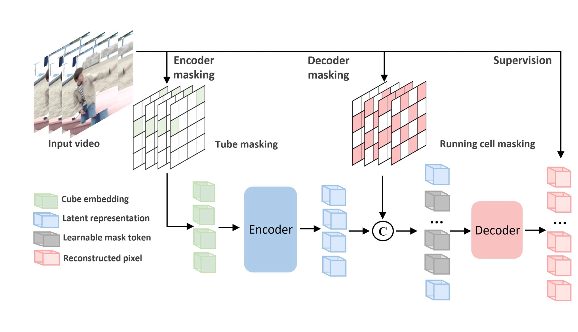
Video masked autoencoders(CVPR 2023)
自监督训练,Encoder masking把一部份挡住,Decoder Masking把挡住的部分替换为可学习的tokens来引导Decoder只预测这一部分
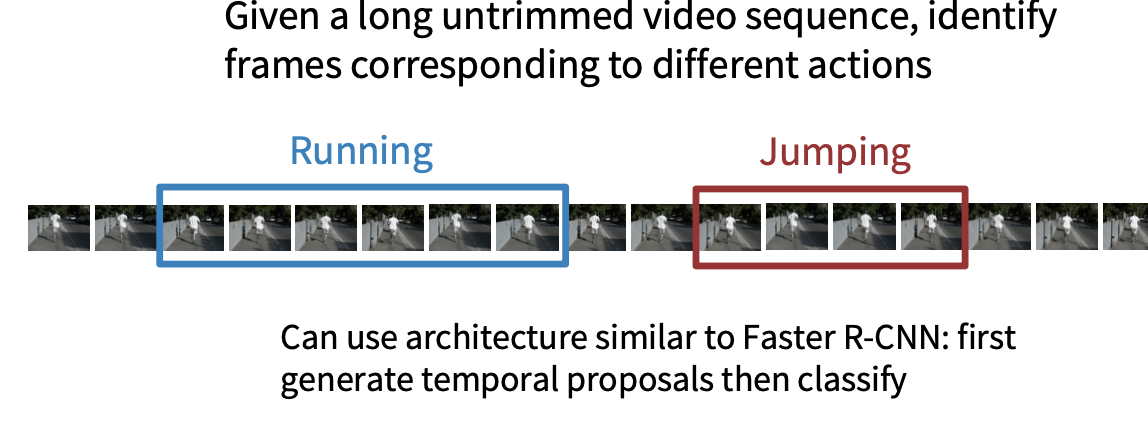
时序动作定位
空间时序检测:视频level的物体分割

视觉引导的音频分离/音乐乐器分离
给一段视频和音频判断那个音频是哪个人/哪个乐器的
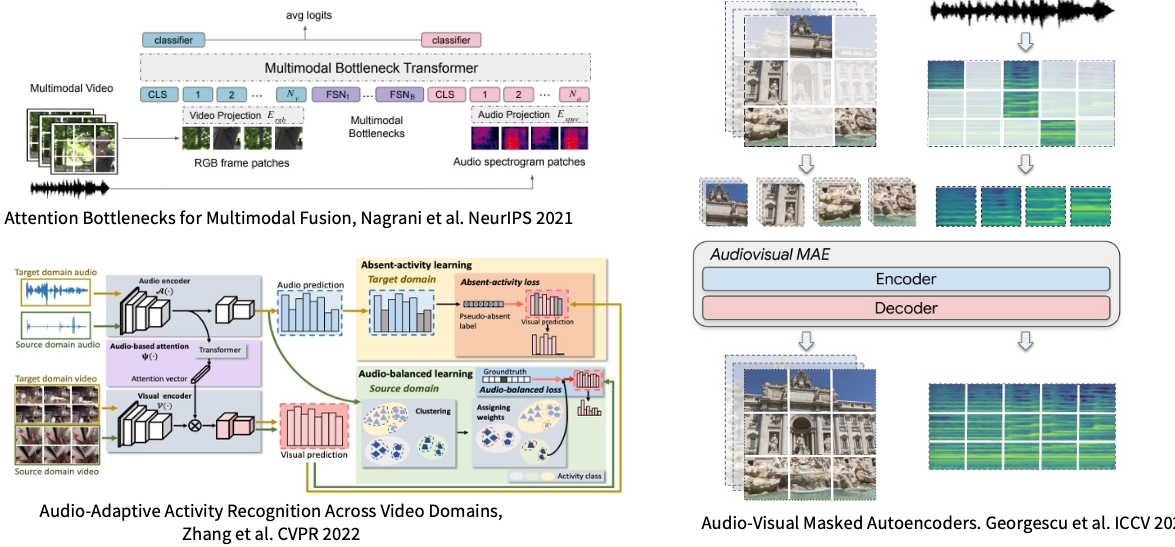
语音视觉多模态视频理解(Audio-Visual Video Understanding)
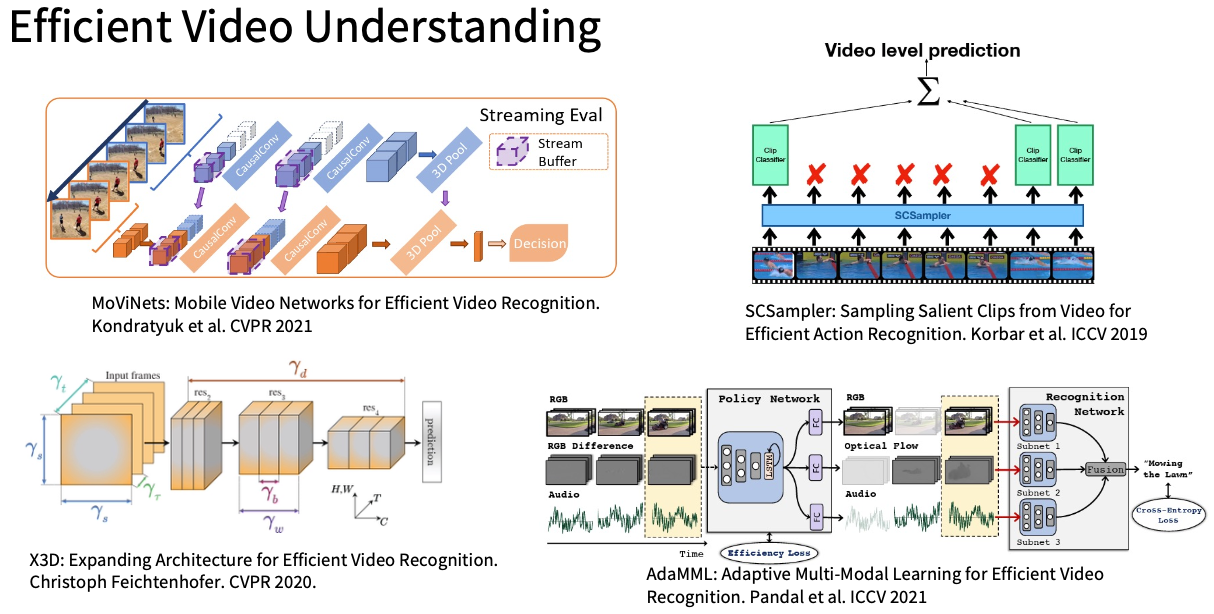
Efficient Video Understanding:长视频中的动作识别理解等
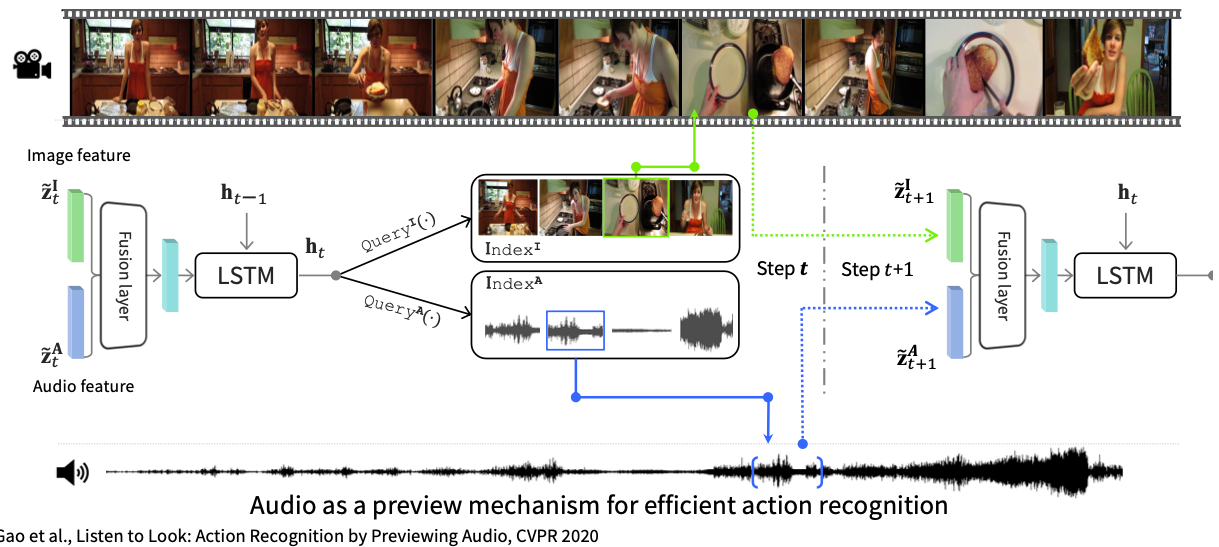
借助大模型的Video Understanding
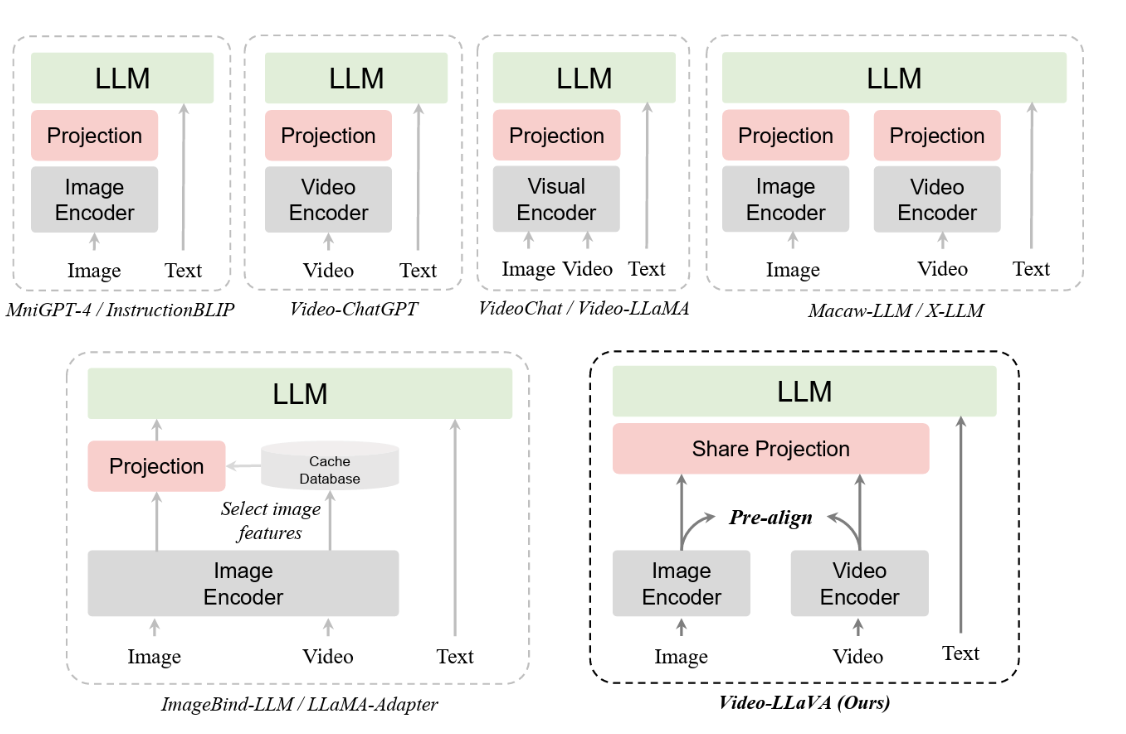
Video-LLaVA
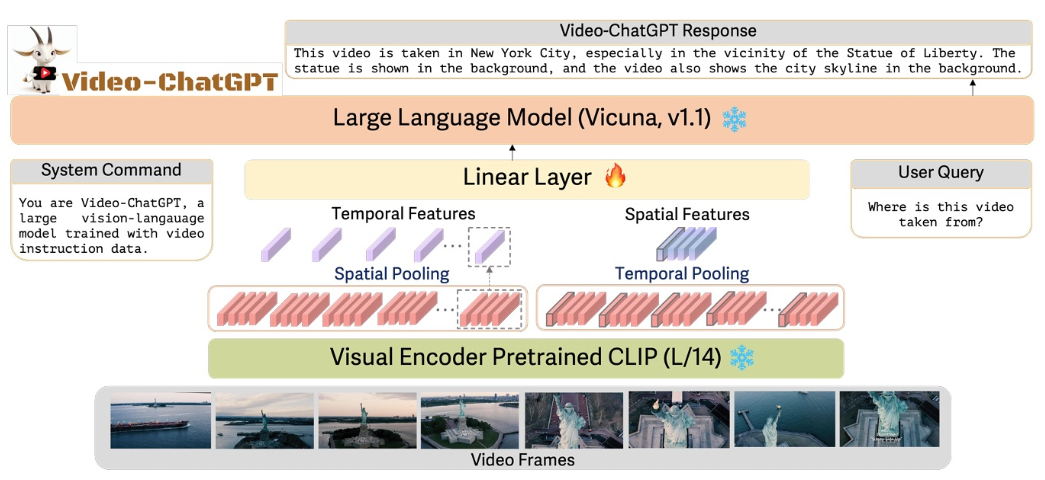
Video-ChatGPT
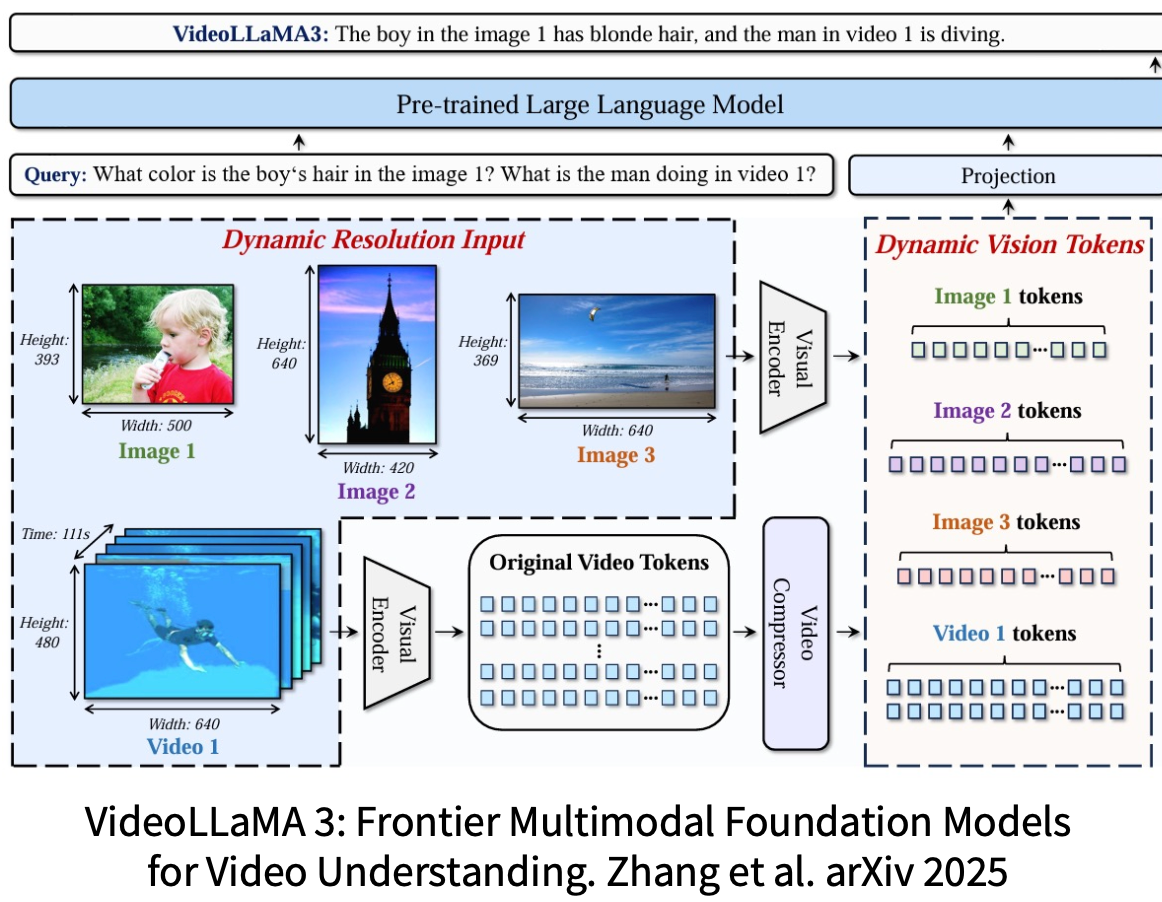
VideoLLaMA3
This post is licensed under CC BY 4.0 by the author.