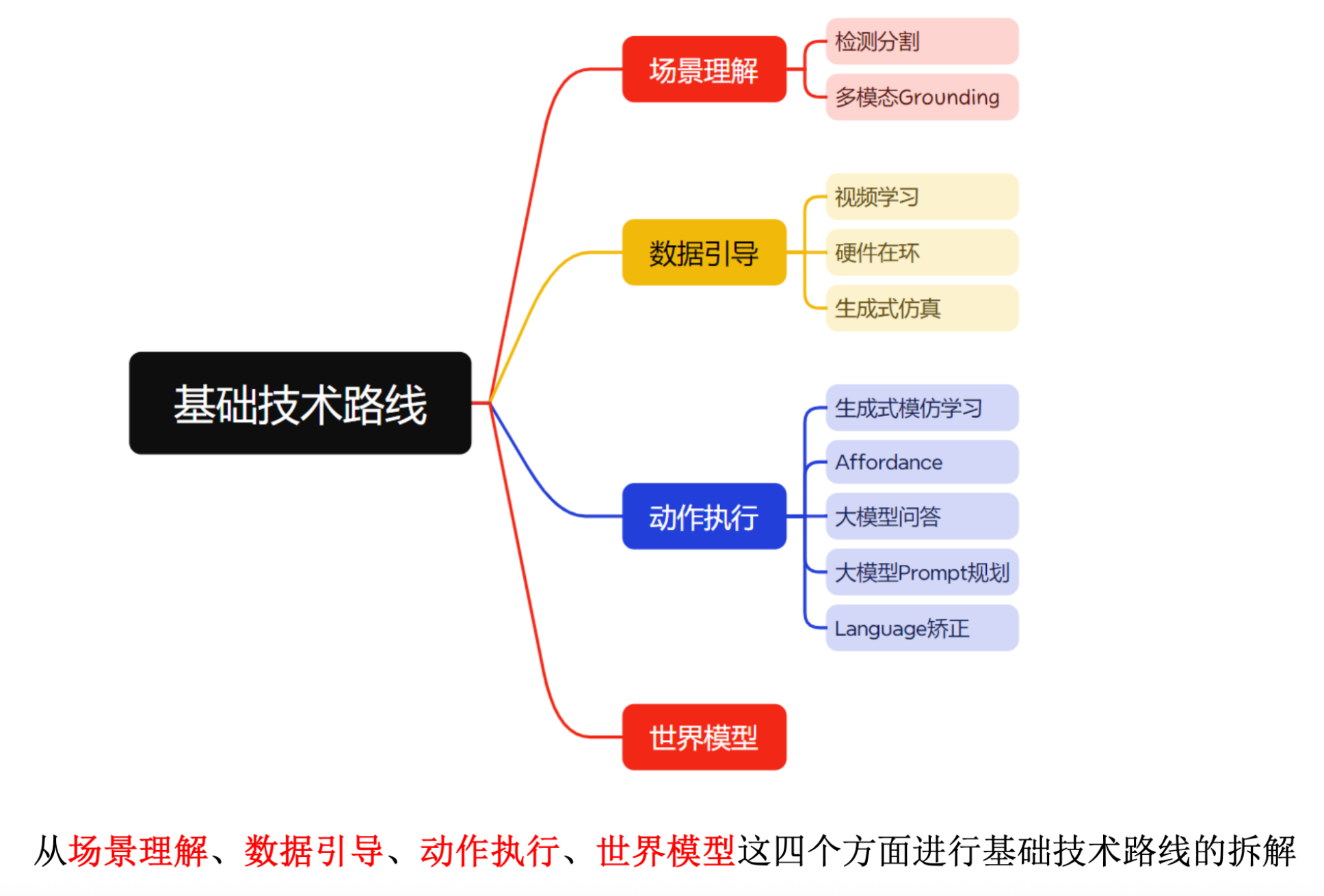
具身智能技术路线入门
具身智能技术路线入门
本文基于YunlongDong 的具身智能基础技术路线Talk进行总结
检测分割
SAM系列
- SAM:进行图片level的分割
- SAM2: 进行video level的分割
- SAM3:promptable segmentation in images and videos
- 衍生产品: SAM3D 可以进行3D物品生成也可以进行人体生成有 object 和body 两个版本
数据
Video
更多paper可以参考(这个仓库好久没更新了后续fork完会持续更新):
- https://github.com/H-Freax/Awesome-Video-Robotic-Papers
优点:
- 最容易获取的数据源
- 海量且多样化的数据
- 以人类全速
缺点:
- 重建过程中存在巨大空白
 和
和
- 状态可能不是第一人称视角,也可以是来自不同的视角角度,引入了较大的状态间隙
- 动作必须完全从原始数据中推断,通常通过 来自其他模型的伪标记过程(例如骨骼追踪器 / 人类手部追踪器),容易误差累积
- 如果没有完整的人体景深,轨迹在运动动力学上可不可行,因为躯干会倾斜、重量转移, 伸手,等等
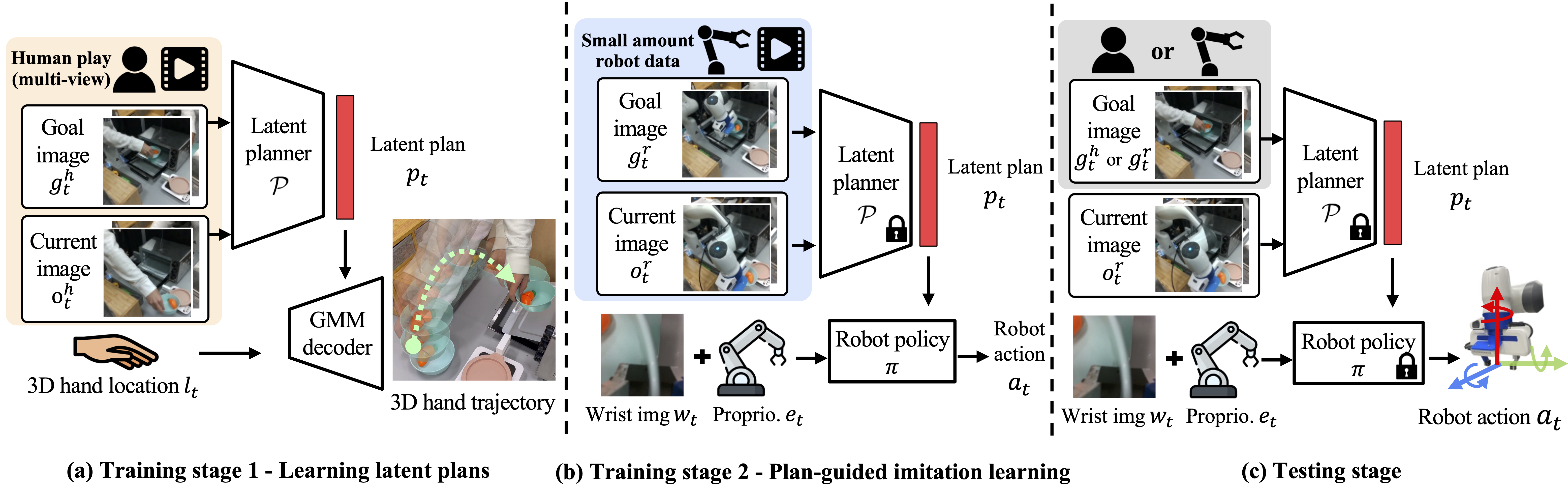
轻量级的硬件收集示范数据
小型设备
- ALOHA : 双臂轻量收集数据设备

- GELLO :

优点:
- 跟随机器人配备了完整的传感器套件,可以记录所有
- 所有演示活动动力学上可行,就他们本来的样子 在机器人上执行
缺点:
- 通常比人类慢得多(最多可达10倍!) 直接用手完成任务
- 操作员需要数周的练习才能熟练 足以让数据用于训练
- 需要现场配备全机器人收集数据——这非常重要 规模化采集的生产与资本需求
手套型设备
DexCap:手套
HIRO Hand :套在手指上的设备来收集示范数据
优点:
- 操作员学习更快
- 更快的演示
- 规模化部署成本更低(例如通用型4, 星期日5)
缺点:
- 噪声重构 和 ,引入一个域间隙可能严重损害策略性能
- 本体感觉和作用需从SLAM推断末端执行器姿态估计
- 摄像机图像中,所有的都是人类手臂拿着装置,但在推断时间,机器人看到的是机器人手臂
- 运动动力学的可行性无法保证——人类可以伸手出去作为演示的一部分,或者用手臂达到机器人无法做到的姿势(人类的工作空间往往比机器人的工作空间大)
重量级的硬件收集
- VR
- 外骨骼
生成式仿真
- RoboGen
- Gen2Sim
- RoboTwin
- InternData-A1
- MimicGen
这也是我最focus 的一个方向所以更多阅读paperlist会在后续开源
动作执行
Imitation Learning
主流Model
ACT:
Diffusion Policy :
\(\pi\) 系列: \(\pi 0\) ,\(\pi_{0.5}\) ,\(\pi_{0.6}\)
缺点:
- out of distribution states :
- 光照等环境变量的突然改变就会导致prediction改变
- partially observation 会导致动作偏移
- 多义性动作比如你绕柱子可以从左边绕也可以从右边绕没有保证.
- prediction error 的accumulation 导致最后完全不像样
摆脱OOD 算法
DAgger: 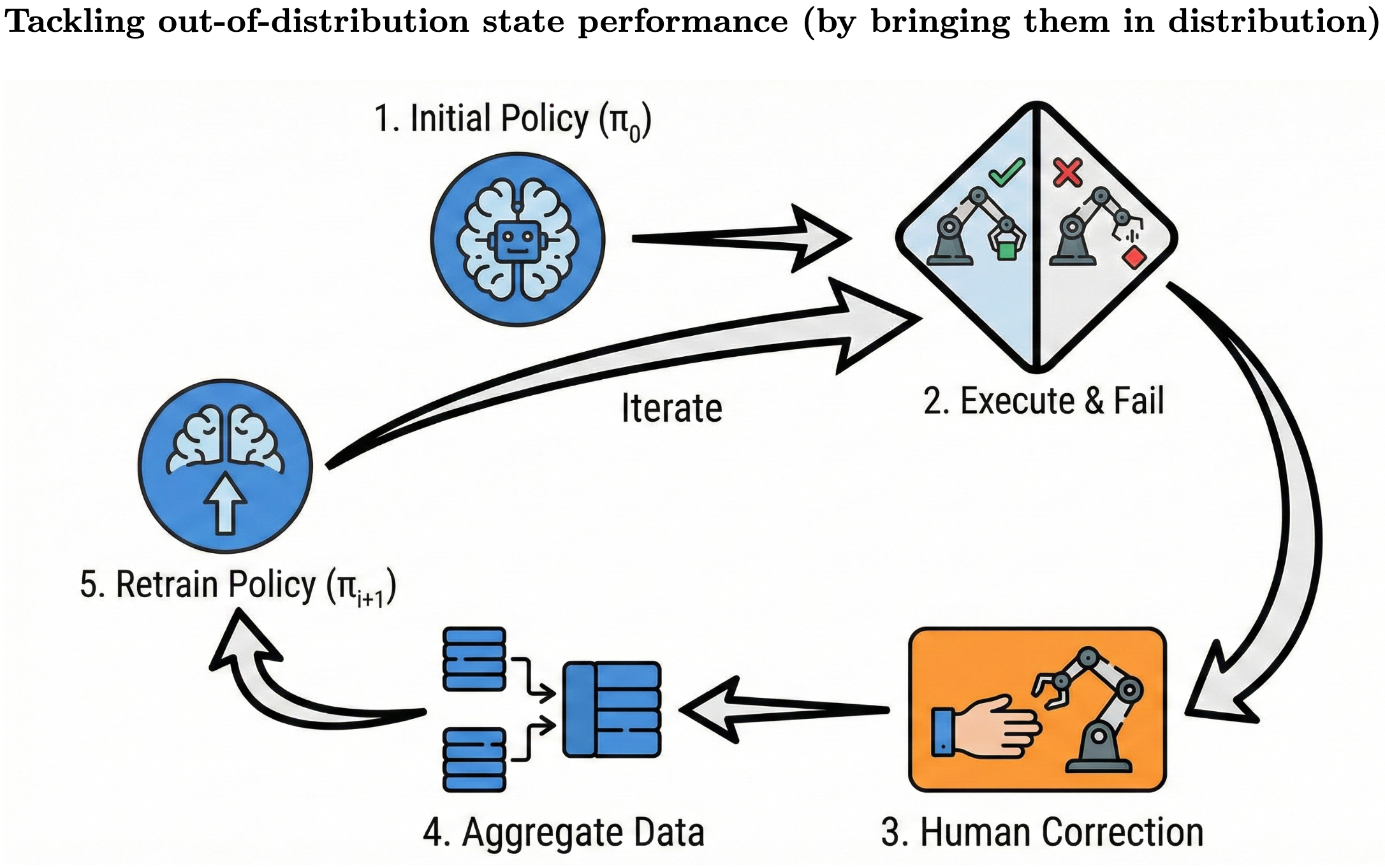
Speed Up Topic
- 保留Fastest Demonstration : 会导致损失大量数据而导致model失去鲁棒性
- condition on speed:
- 把策略的动作以“比真实时间更快”的频率去执行 :(本来策略/控制是 50Hz(每秒 50 次控制指令),你改成 70Hz(每秒 70 次)) 相当于让机器人“快进”跑:
- 会压垮底层控制系统(low-level control stack) 低层控制、通信、驱动、传感器处理都有带宽/延迟/稳定性上限。你强行提高频率,会导致指令来不及处理、抖动、延迟累积,控制环不稳定或性能变差
- 会让与真实物理交互变得不正确 世界的物理过程有“真实时间尺度”:比如物体落下、布料飘落、震动衰减、摩擦滑动停止……这些需要时间发生。 你把控制循环加速,相当于在更短的真实时间里发出更多动作/推进更多决策步,但物理世界并不会跟着“快进”,于是策略里那些“等它稳定/等它落下”的隐含假设就失效。
Affordance:检测物品的可操作部分
RoboAffordance:
AffordPose :
SceneFun3D :
更多paper可以参考: https://github.com/hq-King/Awesome-Affordance-Learning
大模型的应用
利用大模型的QA来采取action
ManipLLM :
ManipVQA :
大模型的planning 能力
World Model
3D VLA
LAPO
Reinforcement Learning
伟大的愿景(自进化系统)
- 自己收集自己的训练数据,并从训练数据中提升.
- 当他们困在bad state, 可以通过自己探索来摆脱, 然后自己学会以后不要再犯
- they can automatically get faster, becoming super-human at the task for their embodiment
相比于大模型RL的区别
大模型:
- LLMs are able to be rolled out an unlimited number of times from the identical state
- LLMs start with a very strong base policy(保证base policy的成功率一定 > 0从而数据飞轮可以转起来)
高质量Paper关注list
高质量会议与期刊(论文检索时重点关注) Science Robotics, TRO, IJRR, JFR, RSS, RAL, IROS, ICRA, ICCV, ECCV, ICML, CVPR, NeurIPS, CoRL, ICLR, AAAI, ACL
长期跟进研究进展与选题调研
- Awesome Humanoid Robot Learning(Yanjie Ze):repo
- Paper Reading List(DeepTimber Community):repo
- Paper List(Yanjie Ze):repo
- RoboScholar / Embodied AI Paper List(Tianxing Chen):repo
- SOTA Paper Rating(Weiyang Jin):website
- Awesome LLM Robotics:repo
- Awesome Video Robotic Papers:repo
- Awesome Embodied Robotics and Agent:repo
- awesome-embodied-vla / va / vln:repo
- Awesome Affordance Learning:repo
- Embodied AI Paper TopConf:repo
- Awesome RL-VLA for Robotic Manipulation (Haoyuan Deng):repo
This post is licensed under CC BY 4.0 by the author.